
eCommerace with Elasticsearch
Introduction
Online shopping has been a core application for the Web since the mid-1990s when the Internet became available to the general public. This article discusses how the open source Elasticsearch database and the Amazon Web Services (AWS) Elasticsearch Service can be used as the foundation for an online shopping website.
To illustrate this application of Elasticsearch, this article discusses a demonstration application, written in Java. This application is implemented using the Spring framework (Spring Boot and Spring MVC).
Topstone Software Consulting uses both the Spring framework and Elasticsearch in building eCommerace applications.
The Java code for this demonstration application is published on GitHub (https://github.com/IanLKaplan/BookSearchES) under the Apache 2 software license.
This application is an expanded version of a similar demonstration application that uses the AWS DynamoDB database (see Spring and DynamoDB and the GitHub repository https://github.com/IanLKaplan/booksearch)
Faceted Search
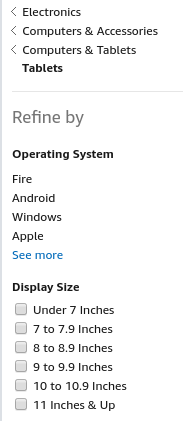
Faceted search is a core feature of most online shopping Web sites.
When you shop at a website like Amazon or Lands End you often use faceted search operations to find the products that you may be interested in purchasing. For example, if you are thinking of purchasing a tablet computer you might follows down the Amazon categories
You can further select the tablet you are interested in by the operating system and the tablet size (in inches).
These search categories (e.g., 10 to 10.9 inch tablets) are sometimes referred to as facets. Search that displays these facets is referred to as faceted search.
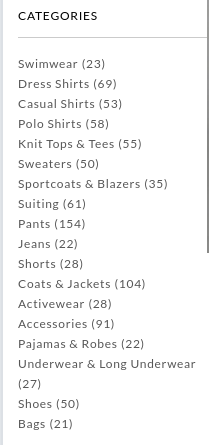
Some websites display the categories (facets) with an associated count. This can be seen in the screen capture from an online clothing retailer. If a category has a large number of items associated with it, this tells the user that they need to use more detailed selection to find the items they are interested in.
Often unstructured search is used to find an item on a retail website. For example, if you are searching for a "G8" LED bulb to replace a halogen bulb, you might search for "g8 led bulb" instead of trying to find the Amazon category for LED light bulbs.
When designing the system architecture for an online shopping site, a database should be choosen that supports both faceted search and unstructured search (the search for the "G8" LED bulb).
The Book Search demonstration application shows how the Elasticsearch database can support both faceted search and full text search. Elasticsearch is built on top of the Apache Lucene database, which has powerful full text search capabilities.
Elasticsearch
Elasticsearch is an open source (Apache license) database that is built on top of the Lucene full text indexing system.
Elasticsearch is a scalable database. When running on a base AWS Elasticsearch Service instance, this application uses a single server. For larger data sets or as the data requirements grow, the Elasticsearch Service instance can be sharded across multiple processing nodes. Distributing the processing load across multiple processing nodes allows the Elasticsearch Service to rapidly deliver search results for very large data sets.
An Elasticsearch instance will have one or more indices and each index will have an associated data type. The Elasticsearch data type is equivalent to a database table schema for a relational database. The Elasticsearch type definition is referred to as a mapping.
An Elasticsearch mapping is flexible and additional fields can be added to a mapping without affecting the existing data (although existing data elements will not have data defined for the new field).
The Elasticsearch index for the Book Search demonstration application is shown below. The name of the index is bookindex. The name of the type associated with this index is bookinfo.
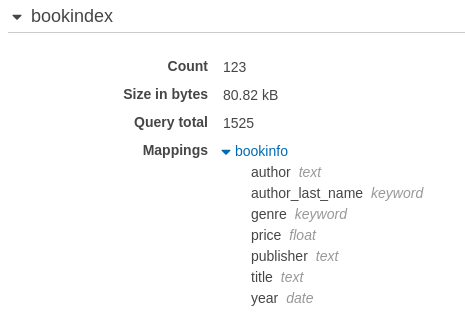
The mapping (schema definition) associated with the Elasticsearch bookindex/book info index/type is shown below.
The text fields can be searched for arbitrary strings. For example, searching for the word "venice" in the bookinfo "title" field will return all of the bookinfo entries that contain the world "venice" in the tile. Searches within text fields ignore character case.
This type of unstructured text search would be used to find the "G8 LED" light bulb on an online shopping site like Amazon.
The keyword type defines a field that is searched by exact match. Searches on the "genre" field must exactly match the strings in that field to return a bookinfo element. For example, a search on "Science Fiction" and a search on "Fiction" return different data elements. For keyword fields, character capitalization matters.
Some fields, like "publisher" are stored as both text fields and keyword fields. This allows the book publisher to be searched as full text and also supports a publisher facet which will display the number of books in the database printed by that publisher.
When data is stored in the "publisher" field, it will update both the text and the keyword parts of the field.
{
"bookindex": {
"mappings": {
"bookinfo": {
"_all": {
"enabled": false
},
"properties": {
"author": {
"type": "text"
},
"author_last_name": {
"type": "keyword"
},
"genre": {
"type": "keyword"
},
"price": {
"type": "float"
},
"publisher": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"year": {
"type": "date",
"format": "YYYY"
}
}
}
}
}
}
The Amazon Elasticsearch Service
Every minute that you spend doing system administration work to manage a database, an operating system or a server is a minute that you are not spending writing software and making your product better.
Amazon Web Services offer a variety of "hosted services" for databases and Web servers. No system administration work is needed for an AWS hosted service beyond deciding when you would like a database software version to be updated.
The Amazon Elasticsearch Service provides hosted instances of Elasticsearch. This allows Elasticsearch to be configured from the Elasticsearch Service Web page. This avoids the complexity of directly configuring an Elasticsearch cluster.
The Elasticsearch Search service runs a recent version of Elasticsearch and allows you to upgrade the version on demand.
The Elasticsearch Service comes with an instance of the Kibana. The Kibana tool allows you to test Elastic search queries against the data in your Elasticsearch Service instance. This feature was very useful when developing the queries used by the Book Search application.
The example below shows a search query in the console pane on the left and the query result (in JSON format) in the right panel.
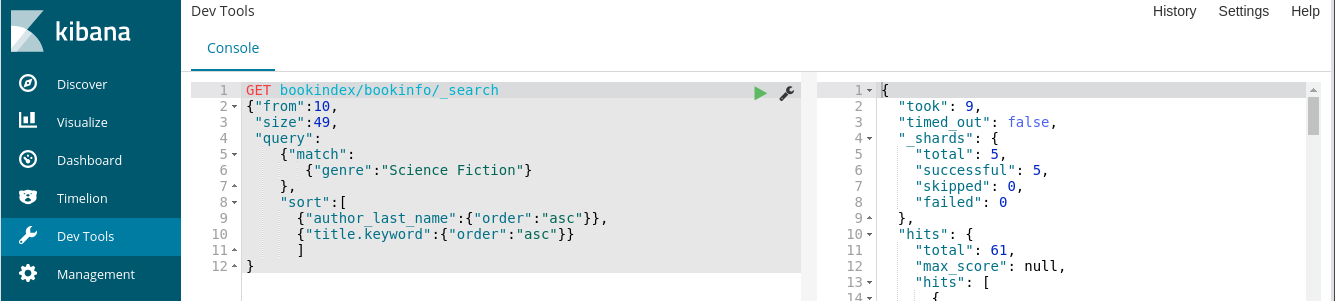
Elasticsearch is a REST Service
Elasticsearch is a Web service and all communication with Elasticsearch takes place over HTTP using the REST operations GET, PUT, POST and DELETE. For example, the Elasticsearch query below uses a GET operation.
GET index/type/_search { "query": { "bool": { "filter": { "match": { "author": "gibson" } } } } }
The query result is returned in the HTTP response as a JSON structure.
HTTP POST operations have an entity (e.g., a string) argument associated with the operation. GET operations were originally designed to fetch data associated with a URL (URI). The GET operation used to query Elasticsearch are an extension of the standard HTTP GET and include an entity (see the HttpGetWithEntity object in the associated Book Search application GitHub source code).
Elasticsearch and Security
An Amazon Elasticsearch Service instance (domain) can be configured as either a public access end-point, which can be accessed from the Internet, or as an Amazon Virtual Private Cloud (VPC) accessible service.
A VPC service has higher security, but debugging and monitoring can be more difficult. When the Elasticsearch Service is configured within a VPC, the HTTP transactions are simpler, since they do not have to be signed and authorized.
The Book Search application is designed to run with an Internet accessible Elasticsearch Service end-point. This makes debugging and testing easier and allows the Book Service application to run on either your local computer system or an Amazon Elastic Beanstalk server. As is the case with most AWS services, access to the Elasticsearch Service end-point can be "locked down" to a single IP address or an IP address range for increased security.
Signed HTTP
The Book Search application uses the Java Apache HTTP Client library for communication with the Elasticsearch Service.
Amazon has published documentation on how to build signed HTTP transactions based on the Apache HTTP Client. Unfortunately, this documentation can be difficult to find. The Book Search application includes AWSRequestSigningApacheInterceptor class which is at the core of these transactions. As with most AWS code, this class is published by Amazon as open source.
The Java code below (available in the associated GitHub repository) shows how this class is used to build signed HTTP objects.
protected static CloseableHttpClient signedClient() { AWS4Signer signer = new AWS4Signer(); signer.setServiceName( SERVICE_NAME ); signer.setRegionName( region.getName() ); AWSCredentials credentials = getCredentials(ES_ID, ES_KEY); AWSCredentialsProvider credProvider = new AWSStaticCredentialsProvider( credentials ); HttpRequestInterceptor interceptor = new AWSRequestSigningApacheInterceptor(SERVICE_NAME, signer, credProvider); return HttpClients.custom() .addInterceptorLast(interceptor) .build(); } protected static String sendHTTPTransaction( HttpUriRequest request ) { String httpResult = null; CloseableHttpClient httpClient = signedClient(); try { HttpResponse response = httpClient.execute(request); BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(response.getEntity().getContent())); httpResult = IOUtils.toString(bufferedReader); } catch (IOException e) { logger.error("HTTP Result error: " + e.getLocalizedMessage()); } return httpResult; }
The code below shows how the sendHTTPTransaction() function is used to send an HTTP get with an entity argument (e.g., the type of GET that is used for a search operation).
public static String getDocument(final String index, final String type, final String suffix, final String jsonPayload) { String responseString = ""; String url = buildURL(index, type, suffix); try { HttpGetWithEntity get = new HttpGetWithEntity( url ); get.setHeader("Content-type", "application/json"); StringEntity stringEntity = new StringEntity( jsonPayload, StandardCharsets.UTF_8); get.setEntity(stringEntity); responseString = sendHTTPTransaction( get ); } catch (Exception e) { logger.error("HttpGet with entity failed: " + e.getLocalizedMessage()); } return responseString; }
For more details, please refer to the Java source code in the associated GitHub repository.
Elasticsearch Documentation
One of the challenges that you will face if you decide to use Elasticsearch is the documentation. In developing the Book Search application and the associated Elasticsearch support code, I relied on four documentation sources:
- Elasticsearch in Action by Radu Gheorghe, Matthew Lee Hinman, and Roy Russo, Manning Publications, November 2015
- The Elasticsearch Reference published on the elastic.co website.
- Amazon Web Services documentation and blog posts on writing Java code to use Elasticsearch and signed HTTP.
- Lots of Google searches to answer questions whose answers I could not find in the above references.
The book Elasticsearch in Action is very useful in understanding the capabilities of Elasticsearch and its architecture. As with most Manning books, the writing quality is high and I recommend reading the first five chapters of this book.
Unfortunately, there are several problems with Elasticsearch in Action as a reference for developing software that uses Elasticsearch. The book is based on Elasticsearch version 2.X. At the time this article was written Elasticsearch is on version 6.X.
There have been significant changes in Elasticsearch between 2.X and 6.X. Some of the queries and other operations described in the book do not work with Elasticsearch version 6.X.
The Elasticsearch architecture has also changed. For example, in Elasticsearch in Action the authors state that there can be multiple types per index. Later versions of Elasticsearch allow only one type per index, making indices and types equivalent.
In Elasticsearch in Action most operations are described in terms of command-line curl operations. For example, a search operation, from Elasticsearch in Action, is shown below.
% curl 'localhost:9200/get-together/group/_search?pretty' -d '{ "query": { "query_string": { "query": "elasticsearch" } } }'
For the Java developer there are few resources to guide the development of Java code for Elasticsearch outside of the Amazon documentation (which is often incomplete and fragmented).
I hope that this article and the associated code on GitHub will provide a useful resource for Java developers. The HTTP and Elasticsearch code is independent of the Book Search demonstration application and you may freely use it in your own applications.
Running the Book Search Application
The Elasticsearch based Book Search application can be cloned from its GitHub repository.
The Book Search application is built using the Spring framework (Spring Boot and Spring MVC). To build the application you will need to install the Spring Tool Suite (STS), which is a version of Eclipse customized for the Spring framework. The STS project uses Maven to load the necessary Java libraries.
To run the application you will need an Amazon Web Services account and you will need to configure an Elasticsearch Service domain. You will also need to use Amazon's IAM service to obtain an ID and a secret key for Elasticsearch Service full access. The ID and key should be added to the IElasticsearch Java Interface in the code base. You will also need to add your Elasticsearch end-point URL to the Interface.
When you run the Book Search application it will create an index and load a mapping. You can load test data from the books.json file using the LoadESFromJSON utility program.
The Book Search Application
The Elasticsearch version of the book search application expands on the Book Search application that uses DynamoDB with the addition of an "Explore" page that showcases some of the features Elasticsearch. The "explore" tab is shown below. This tab allows the user to explore the book database by genre or publisher.
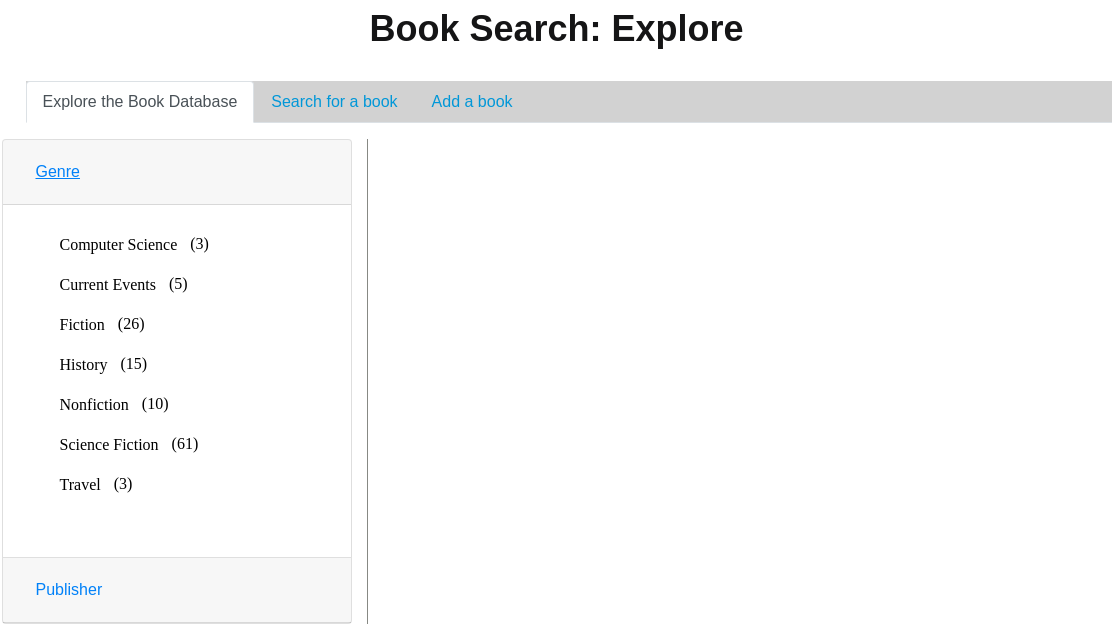
The "genre" accordion tab is expanded to show the book genres, with their associated book counts.
The "Search for a book" tab allows the user to search by author, title or title and author.
The DynamoDB application requires an exact author name or book title. Since this version of the Boook Search application uses the Elasticsearch database, partial author names or titles can be used in the search. For example, entering the word "venice" in the title search dialog will return the books with "venice" in their title.
Amazon Cloud Architecture, Spring and Elasticsearch Consulting
Topstone Software has extensive experience building scalable web applications on Amazon Web Services. We can help you design your AWS application architecture to provide scalability and optimized cost.
We designed and built the nderground social network. nderground is a social network designed for privacy and security. nderground has been live with close to 100% uptime for over three years.
At Topstone Software we have experience building Spring framework applications that utilize a variety of AWS services. These include Elasticsearch, DynamoDB, S3, the Simple Email System and Elastic Beanstalk. We can provide the consulting help to speed your application development or we can develop applications to your specification.